YouTubeのサムネイル画像からVTuberグループホロライブのメンバー(ホロメン)を検出する機械学習モデルをSSD300(Single Shot Multibox Detector)で実装した.また,推論を実行して結果を表示するインタフェースをWebサイトとして公開した.
特に工夫した点 #
- 訓練画像の枚数と各メンバーのラベル数
- データオーグメンテーション
- モデルにデータを食わせる順番
訓練画像の枚数と各メンバーのラベル回数 #
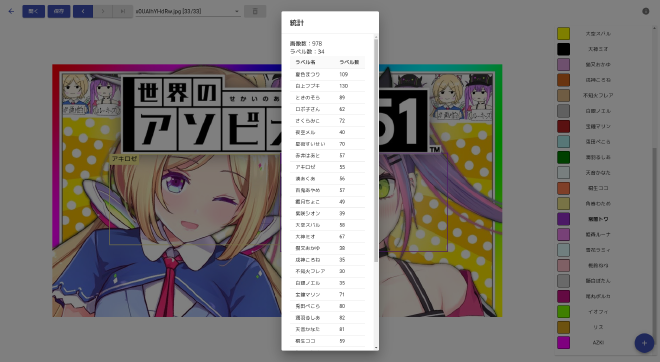
YouTubeのサムネイル画像を900枚程度用意した.各画像にはLive 2Dモデルのメンバーが一人以上写っている.各メンバーにつき30回以上ラベル付けされるように画像数を増やした.ラベル付け回数の確認は下図のような画面を実装して確認した.
データオーグメンテーション #
画像を1/3から3倍のスケールでランダムに拡大・縮小し,拡大した画像に対してはランダムな位置でクロップ,縮小した画像に対してはランダムな位置に配置し黒でパディングする処理を実装した.処理の例を以下に示す.左の画像が元画像,中央と右の画像がそれぞれ拡大・縮小した画像.アスペクト比が変わらないように処理している.



訓練画像の前処理のコードは次のようになっている.
class Transform():
def __init__(self):
self.transform = Compose([
RandomScaleCrop(0.33, 3),
Resize(300), # 300x300にリサイズ
ToTensor(),
])
def __call__(self, image, boxes, labels):
return self.transform(image, boxes, labels)
モデルにデータを入力する順番 #
「Heの初期化」したモデルにいきなりデータオーグメンテーションした画像を入力すると,ロスが発散してしまい学習が進まない.なので,一旦元画像で100epoch学習させた後に,データオーグメンテーションした画像を学習させるという方法をとった.
訓練画像の収集とラベル付け #
訓練用画像を910枚,検証用画像を68枚用意した.各画像にはLive 2Dモデルのメンバーが一人以上写っている.34ラベルでラベル付けを行った.ラベル付けアプリはelectronで自作した.

SSDの実装 #
PyTorchで実装した.SSDと前処理クラス・訓練関数の実装は 「つくりながら学ぶ!PyTorchによる発展ディープラーニング」小川雄太郎著を参考に実装した.2.8章にPyTorch >= 1.5では動かないコードがあったが, ここを見て解決した.
学習 #
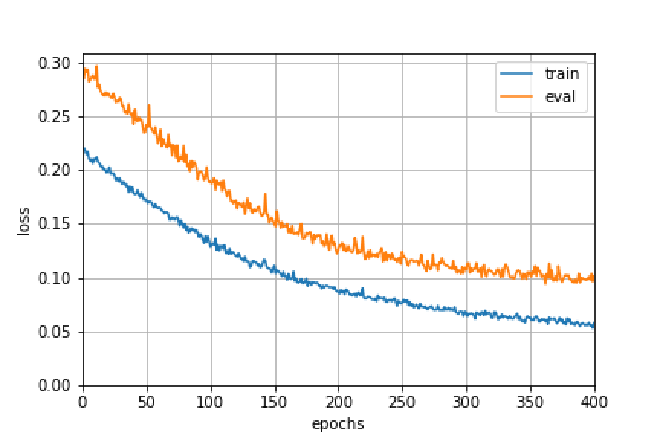
学習済みモデルを用いずに,「Heの初期値」で初期化した状態から学習した.元画像で100epoch+データオーグメンテーションして400epoch回した.後半の400epochの誤差曲線を図に示す.青線がtrain,黄線がeval.バッチサイズは32.Google Colabで19時間程度要した.学習済みモデルのファイルサイズは108MBになった.
推論 #
推論結果の例を以下に示す.推論結果の確信度の閾値は0.6とし,それ以上のボックスを検出したものとした.
うまくいったもの #




うまくいかなかったもの #




検出されないもしくは誤検出されるメンバーは,訓練データを増やすと解決すると思われる.領域が小さいために検出されない場合は,訓練データのラベル領域の中央だけ切り取って学習させるなどすると上手くいくと思っている.
Webアプリの実装 #
Google Cloud RunにPyTorchと訓練済みモデルを載せてクラウド関数を作った.Google Cloud Functionsに載せなかった理由は,モデルのファイルサイズがクラウド関数にアップロードできるサイズを超えていたから.
感想 #
- SSDを用いて画像から2Dモデルを検出するタスクを実践できた.
- 機械学習モデルをWebアプリとしてデプロイできた.
データオーグメンテーションが上手くいって精度が向上したときはテンションが上がった.